
==作者:cybsky==
[toc]
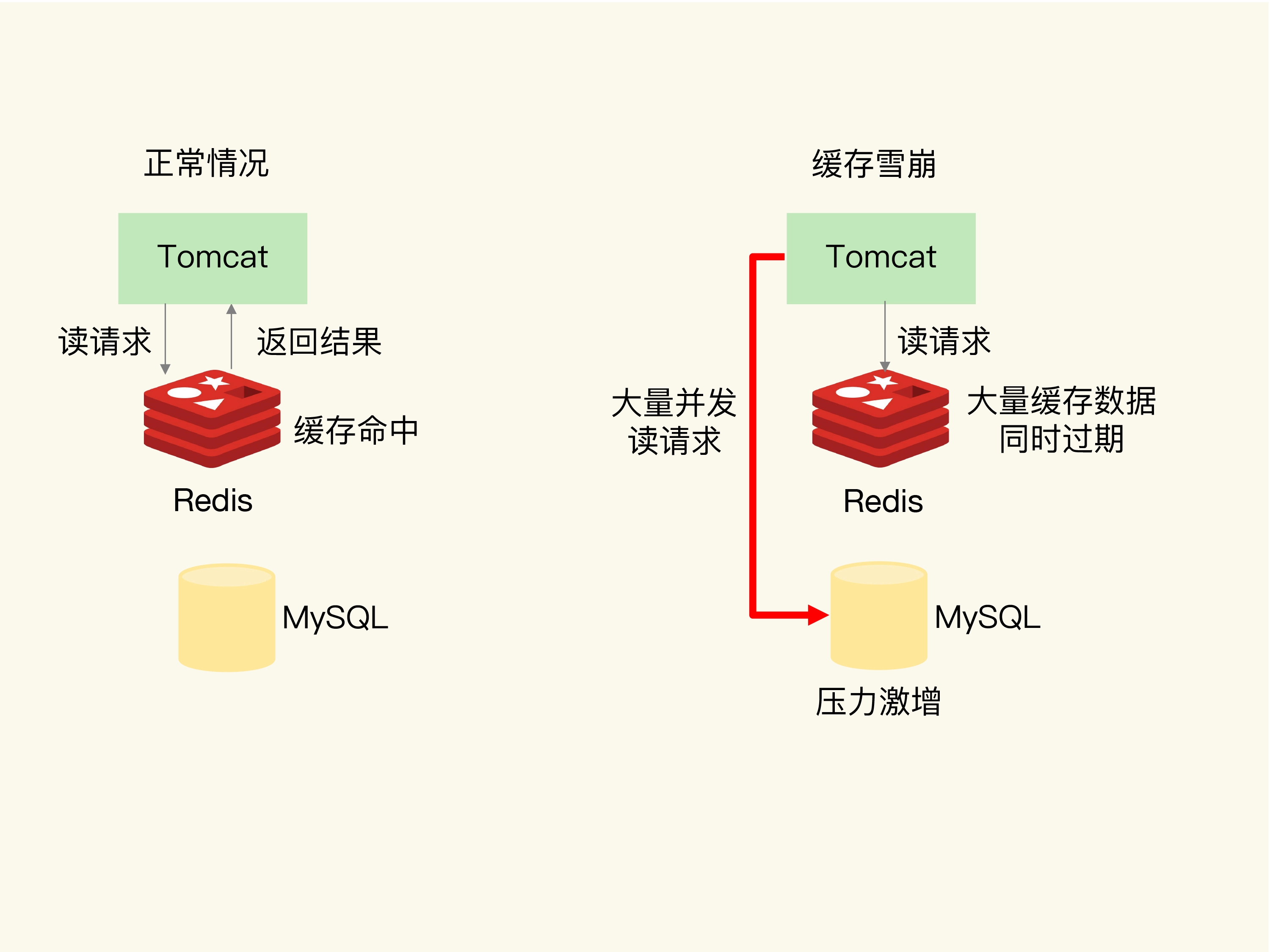
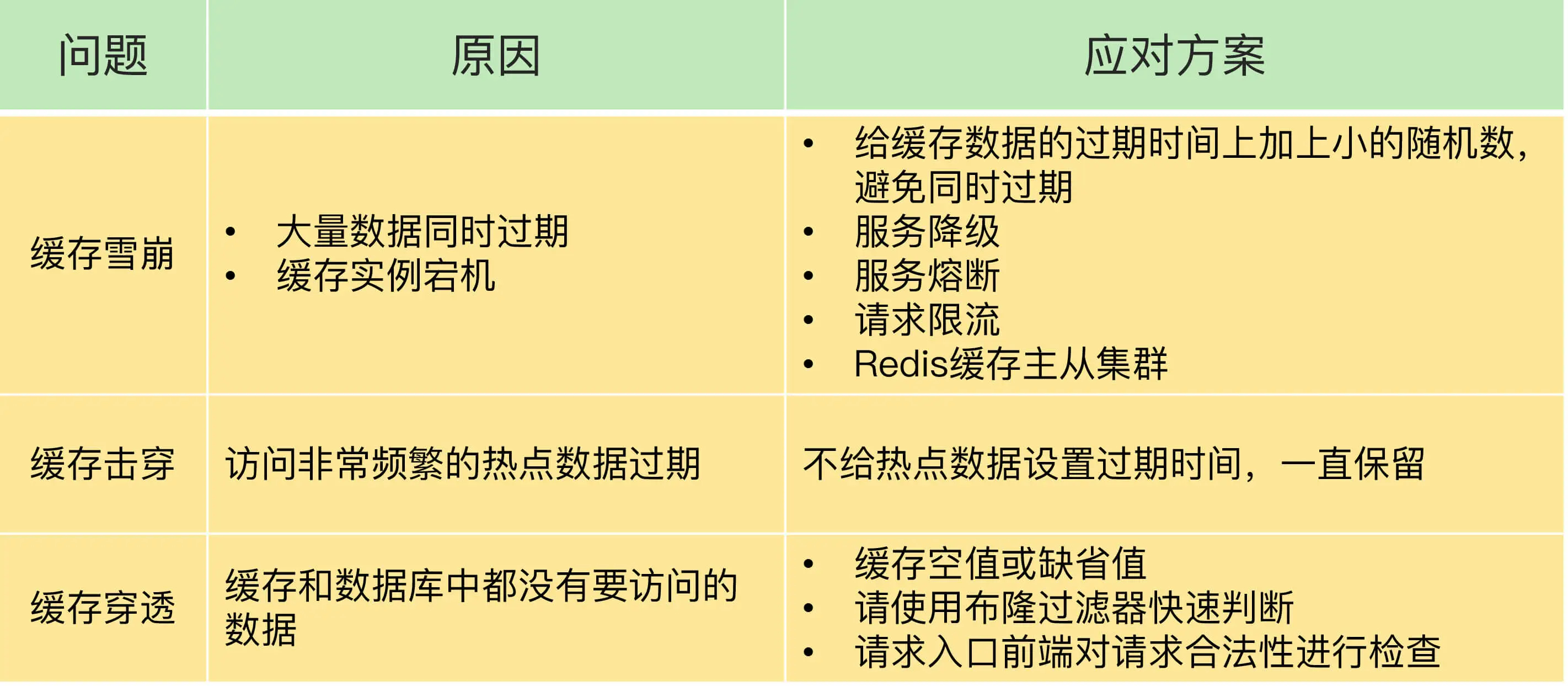
缓存雪崩
缓存雪崩是指大量的应用请求无法在Redis缓存中进行处理,紧接着,应用将大量请求发送到数据库层,导致数据库层的压力激增。
缓存雪崩一般是由两个原因导致的,应对方案也有所不同,我们一个个来看。
第一个原因是:缓存中有大量数据同时过期,导致大量请求无法得到处理。
针对大量数据同时失效带来的缓存雪崩问题,我给你提供两种解决方案。
微调过期时间:
我们可以避免给大量的数据设置相同的过期时间。如果业务层的确要求有些数据同时失效,你可以在用EXPIRE命令给每个数据设置过期时间时,给这些数据的过期时间增加一个较小的随机数(例如,随机增加1~3分钟),这样一来,不同数据的过期时间有所差别,但差别又不会太大,既避免了大量数据同时过期,同时也保证了这些数据基本在相近的时间失效,仍然能满足业务需求。
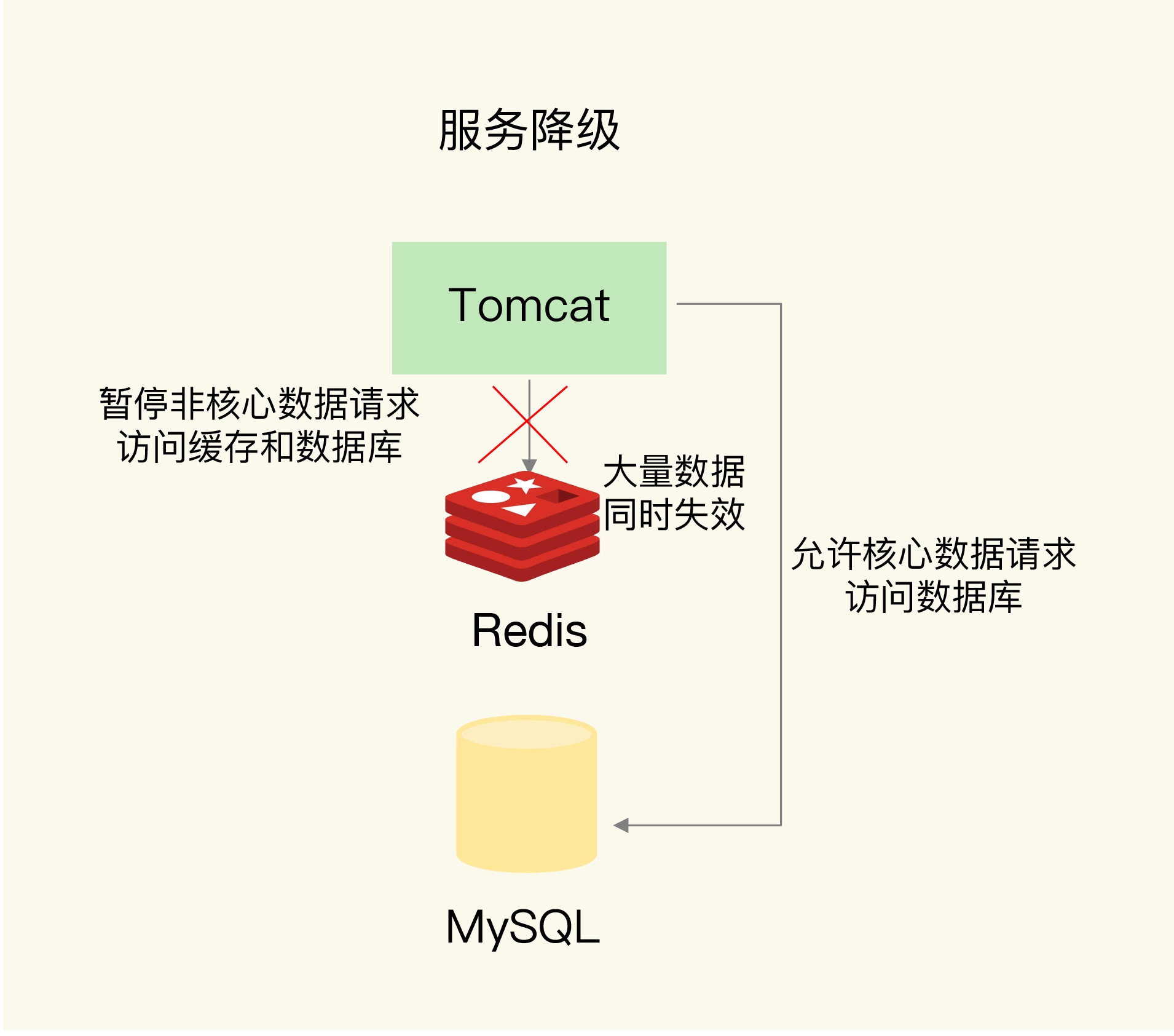
服务降级:
所谓的服务降级,是指发生缓存雪崩时,针对不同的数据采取不同的处理方式。
- 当业务应用访问的是非核心数据(例如电商商品属性)时,暂时停止从缓存中查询这些数据,而是直接返回预定义信息、空值或是错误信息;
- 当业务应用访问的是核心数据(例如电商商品库存)时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取。
这样一来,只有部分过期数据的请求会发送到数据库,数据库的压力就没有那么大了。
第二个原因是:Redis缓存实例发生故障宕机了,无法处理请求,这就会导致大量请求一下子积压到数据库层,从而发生缓存雪崩。
一般来说,一个Redis实例可以支持数万级别的请求处理吞吐量,而单个数据库可能只能支持数千级别的请求处理吞吐量,它们两个的处理能力可能相差了近十倍。由于缓存雪崩,Redis缓存失效,所以,数据库就可能要承受近十倍的请求压力,从而因为压力过大而崩溃。
因为Redis实例发生了宕机,我们需要通过其他方法来应对缓存雪崩了。我给你提供两个建议。
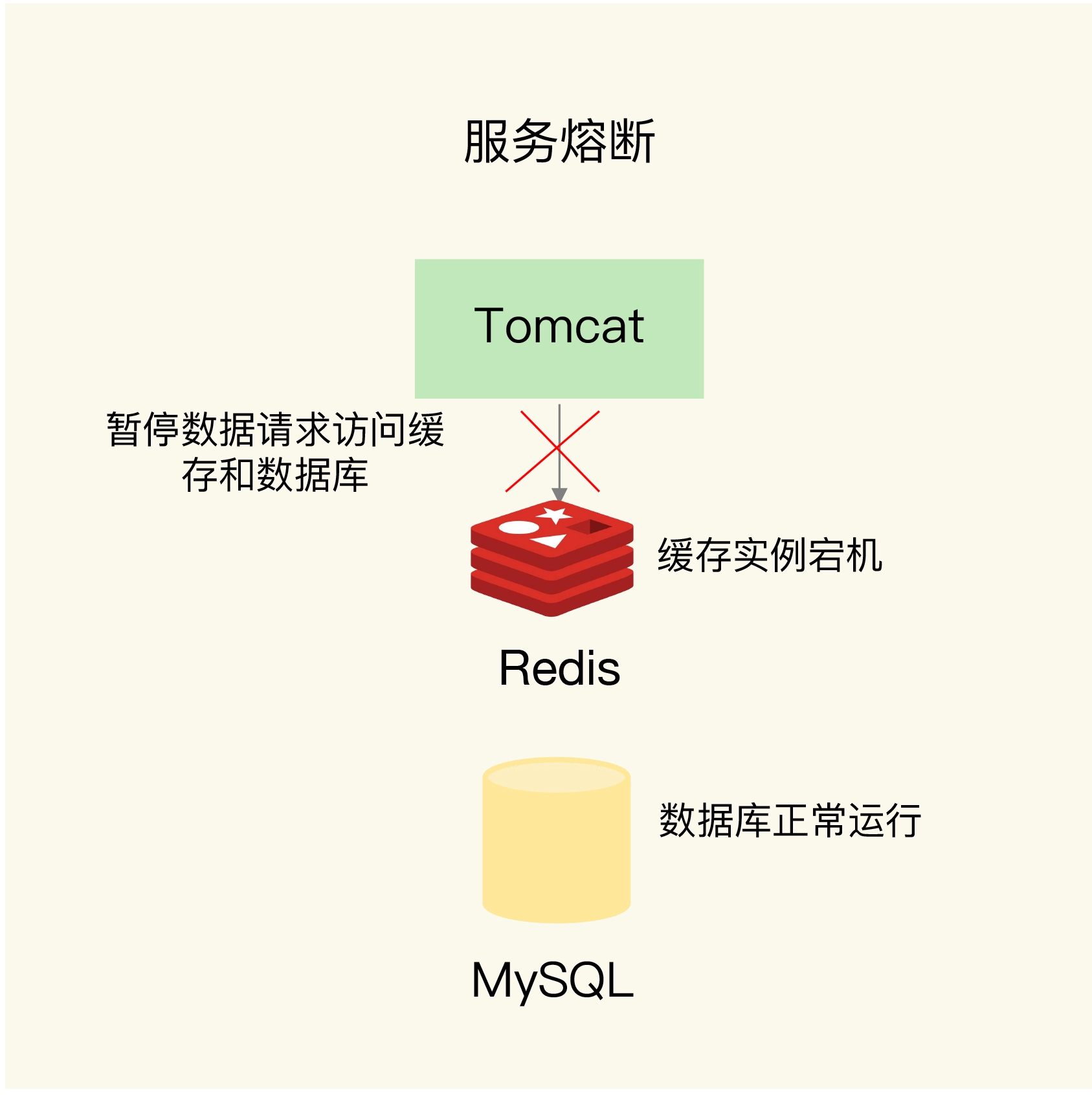
是在业务系统中实现服务熔断或请求限流机制。
- 服务熔断,是指在发生缓存雪崩时,为了防止引发连锁的数据库雪崩,甚至是整个系统的崩溃,我们暂停业务应用对缓存系统的接口访问。再具体点说,就是业务应用调用缓存接口时,缓存客户端并不把请求发给Redis缓存实例,而是直接返回,等到Redis缓存实例重新恢复服务后,再允许应用请求发送到缓存系统。这样一来,我们就避免了大量请求因缓存缺失,而积压到数据库系统,保证了数据库系统的正常运行。服务熔断虽然可以保证数据库的正常运行,但是暂停了整个缓存系统的访问,对业务应用的影响范围大。为了尽可能减少这种影响,我们也可以进行请求限流。
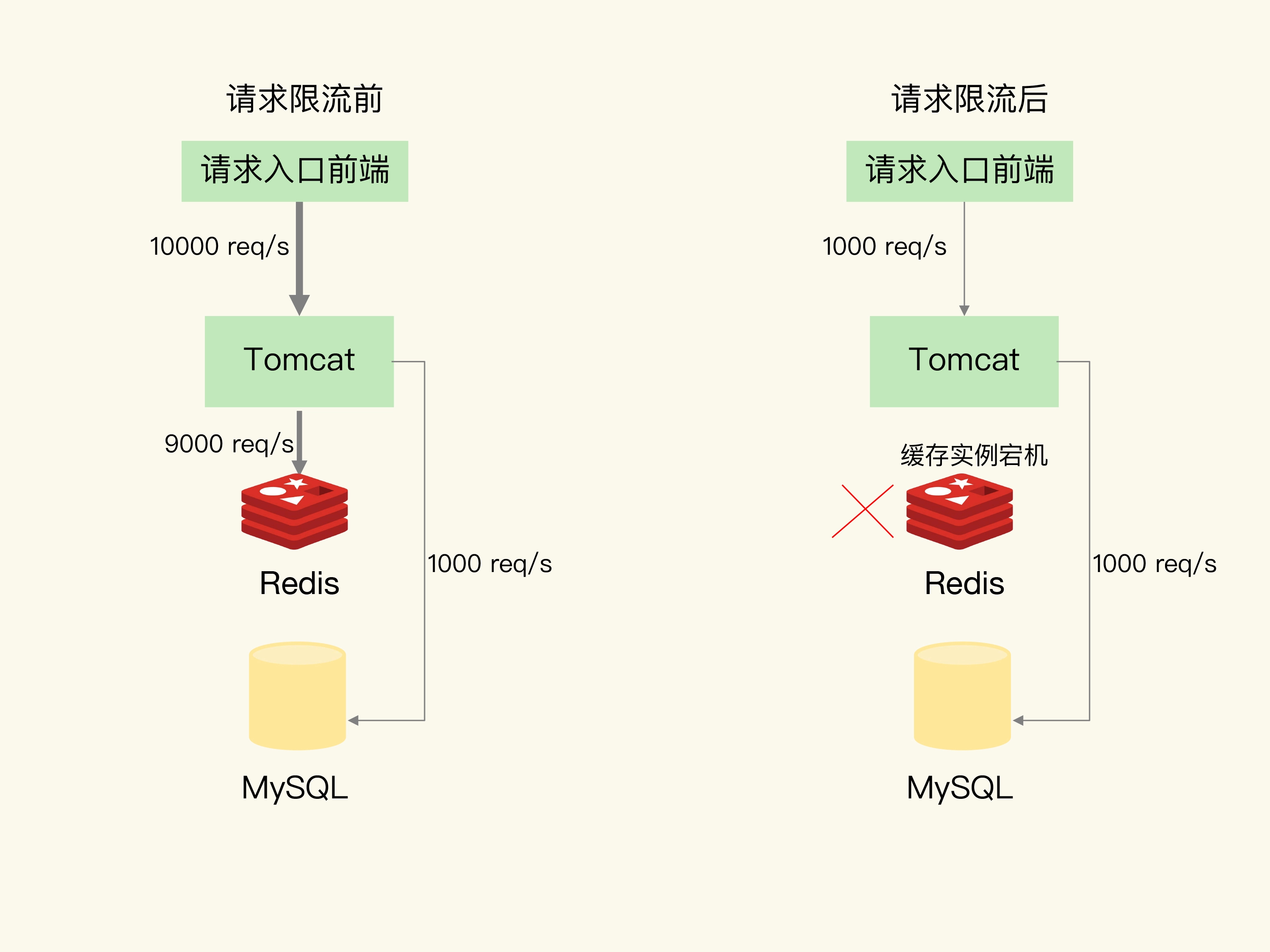
- 请求限流,就是指,我们在业务系统的请求入口前端控制每秒进入系统的请求数,避免过多的请求被发送到数据库。假设业务系统正常运行时,请求入口前端允许每秒进入系统的请求是1万个,其中,9000个请求都能在缓存系统中进行处理,只有1000个请求会被应用发送到数据库进行处理。一旦发生了缓存雪崩,数据库的每秒请求数突然增加到每秒1万个,此时,我们就可以启动请求限流机制,在请求入口前端只允许每秒进入系统的请求数为1000个,再多的请求就会在入口前端被直接拒绝服务。所以,使用了请求限流,就可以避免大量并发请求压力传递到数据库层。
事前预防
通过主从节点的方式构建Redis缓存高可靠集群。如果Redis缓存的主节点故障宕机了,从节点还可以切换成为主节点,继续提供缓存服务,避免了由于缓存实例宕机而导致的缓存雪崩问题。
缓存击穿
缓存击穿是指,针对某个访问非常频繁的热点数据的请求,无法在缓存中进行处理,紧接着,访问该数据的大量请求,一下子都发送到了后端数据库,导致了数据库压力激增,会影响数据库处理其他请求。缓存击穿的情况,经常发生在热点数据过期失效时。
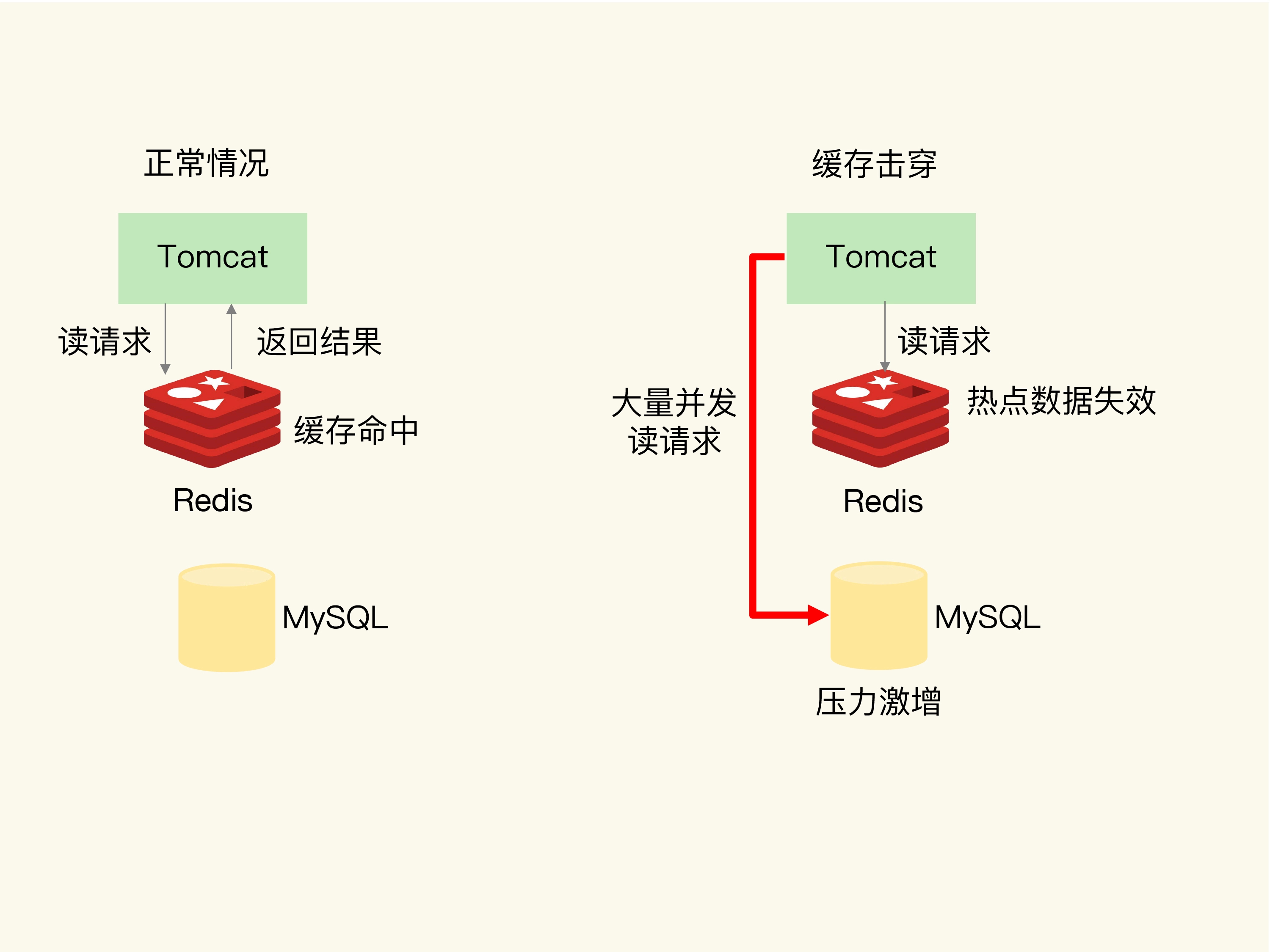
为了避免缓存击穿给数据库带来的激增压力,我们的解决方法也比较直接,对于访问特别频繁的热点数据,我们就不设置过期时间了。这样一来,对热点数据的访问请求,都可以在缓存中进行处理,而Redis数万级别的高吞吐量可以很好地应对大量的并发请求访问。
缓存穿透
缓存穿透是指要访问的数据既不在Redis缓存中,也不在数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据。此时,应用也无法从数据库中读取数据再写入缓存,来服务后续请求,这样一来,缓存也就成了“摆设”,如果应用持续有大量请求访问数据,就会同时给缓存和数据库带来巨大压力
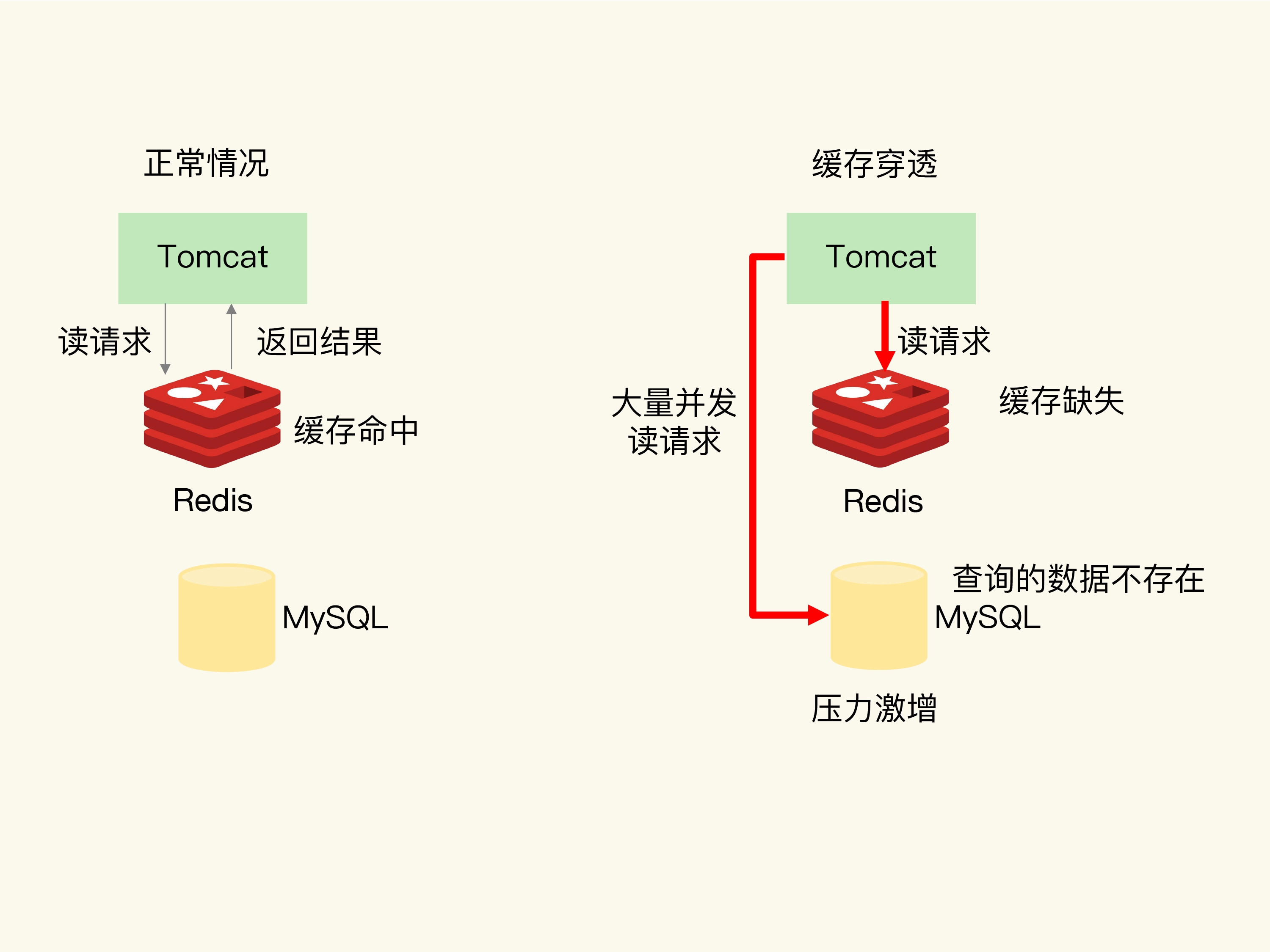
那么,缓存穿透会发生在什么时候呢?一般来说,有两种情况。
- 业务层误操作:缓存中的数据和数据库中的数据被误删除了,所以缓存和数据库中都没有数据;
- 恶意攻击:专门访问数据库中没有的数据。
为了避免缓存穿透的影响,我来给你提供三种应对方案。
缓存空值或缺省值。
一旦发生缓存穿透,我们就可以针对查询的数据,在Redis中缓存一个空值或是和业务层协商确定的缺省值(例如,库存的缺省值可以设为0)。紧接着,应用发送的后续请求再进行查询时,就可以直接从Redis中读取空值或缺省值,返回给业务应用了,避免了把大量请求发送给数据库处理,保持了数据库的正常运行。
前端进行请求检测
缓存穿透的一个原因是有大量的恶意请求访问不存在的数据,所以,一个有效的应对方案是在请求入口前端,对业务系统接收到的请求进行合法性检测,把恶意的请求(例如请求参数不合理、请求参数是非法值、请求字段不存在)直接过滤掉,不让它们访问后端缓存和数据库。这样一来,也就不会出现缓存穿透问题了。
使用布隆过滤器快速判断数据是否存在,避免从数据库中查询数据是否存在,减轻数据库压力。
我们先来看下,布隆过滤器是如何工作的。
布隆过滤器由一个初值都为0的bit数组和N个哈希函数组成,可以用来快速判断某个数据是否存在。当我们想标记某个数据存在时(例如,数据已被写入数据库),布隆过滤器会通过三个操作完成标记:
- 首先,使用N个哈希函数,分别计算这个数据的哈希值,得到N个哈希值。
- 然后,我们把这N个哈希值对bit数组的长度取模,得到每个哈希值在数组中的对应位置。
- 最后,我们把对应位置的bit位设置为1,这就完成了在布隆过滤器中标记数据的操作。
如果数据不存在(例如,数据库里没有写入数据),我们也就没有用布隆过滤器标记过数据,那么,bit数组对应bit位的值仍然为0。
当需要查询某个数据时,我们就执行刚刚说的计算过程,先得到这个数据在bit数组中对应的N个位置。紧接着,我们查看bit数组中这N个位置上的bit值。只要这N个bit值有一个不为1,这就表明布隆过滤器没有对该数据做过标记,所以,查询的数据一定没有在数据库中保存。
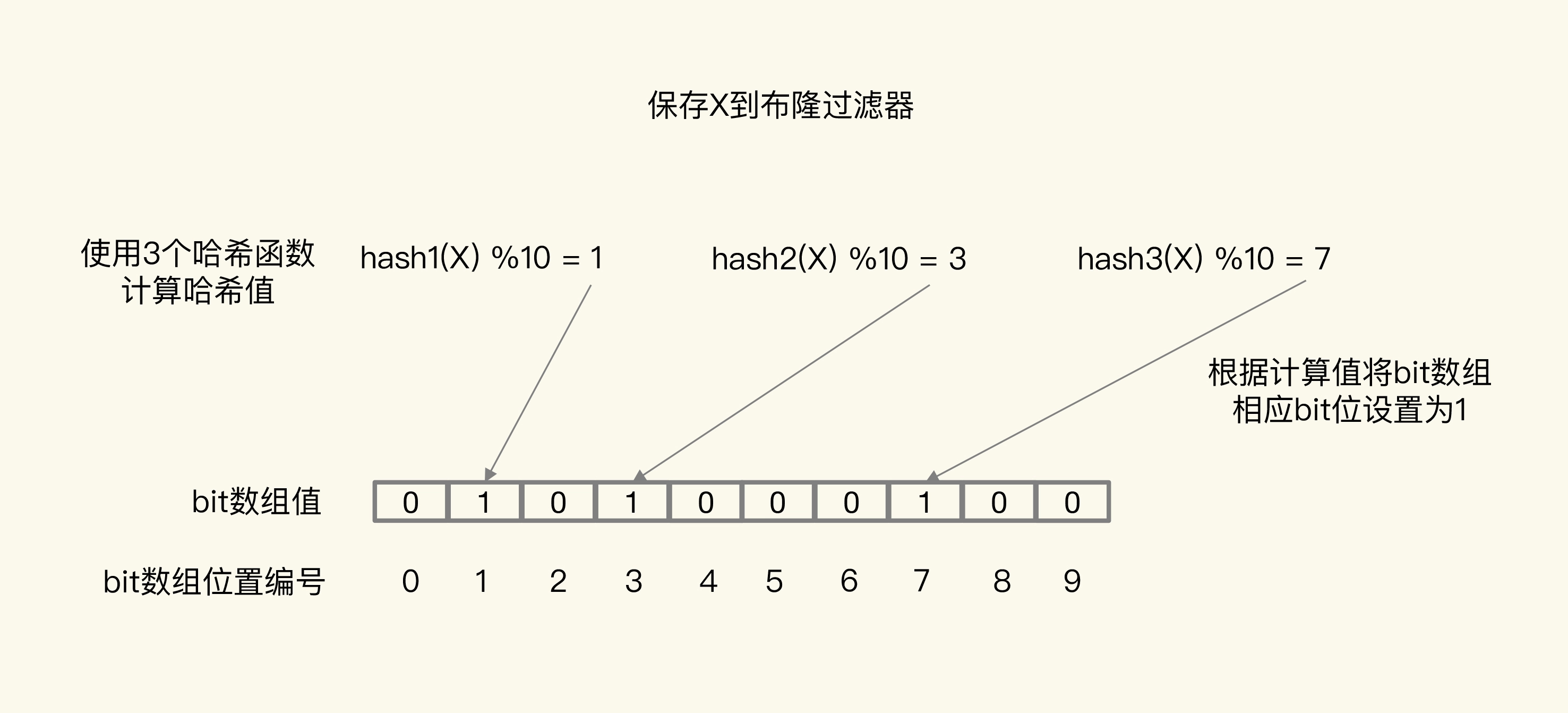
图中布隆过滤器是一个包含10个bit位的数组,使用了3个哈希函数,当在布隆过滤器中标记数据X时,X会被计算3次哈希值,并对10取模,取模结果分别是1、3、7。所以,bit数组的第1、3、7位被设置为1。当应用想要查询X时,只要查看数组的第1、3、7位是否为1,只要有一个为0,那么,X就肯定不在数据库中。
正是基于布隆过滤器的快速检测特性,我们可以在把数据写入数据库时,使用布隆过滤器做个标记。当缓存缺失后,应用查询数据库时,可以通过查询布隆过滤器快速判断数据是否存在。如果不存在,就不用再去数据库中查询了。这样一来,即使发生缓存穿透了,大量请求只会查询Redis和布隆过滤器,而不会积压到数据库,也就不会影响数据库的正常运行。布隆过滤器可以使用Redis实现,本身就能承担较大的并发访问压力。
总结
摘选自:极客时间-Redis核心技术与实战