
==作者:cybsky==
[toc]
jvm
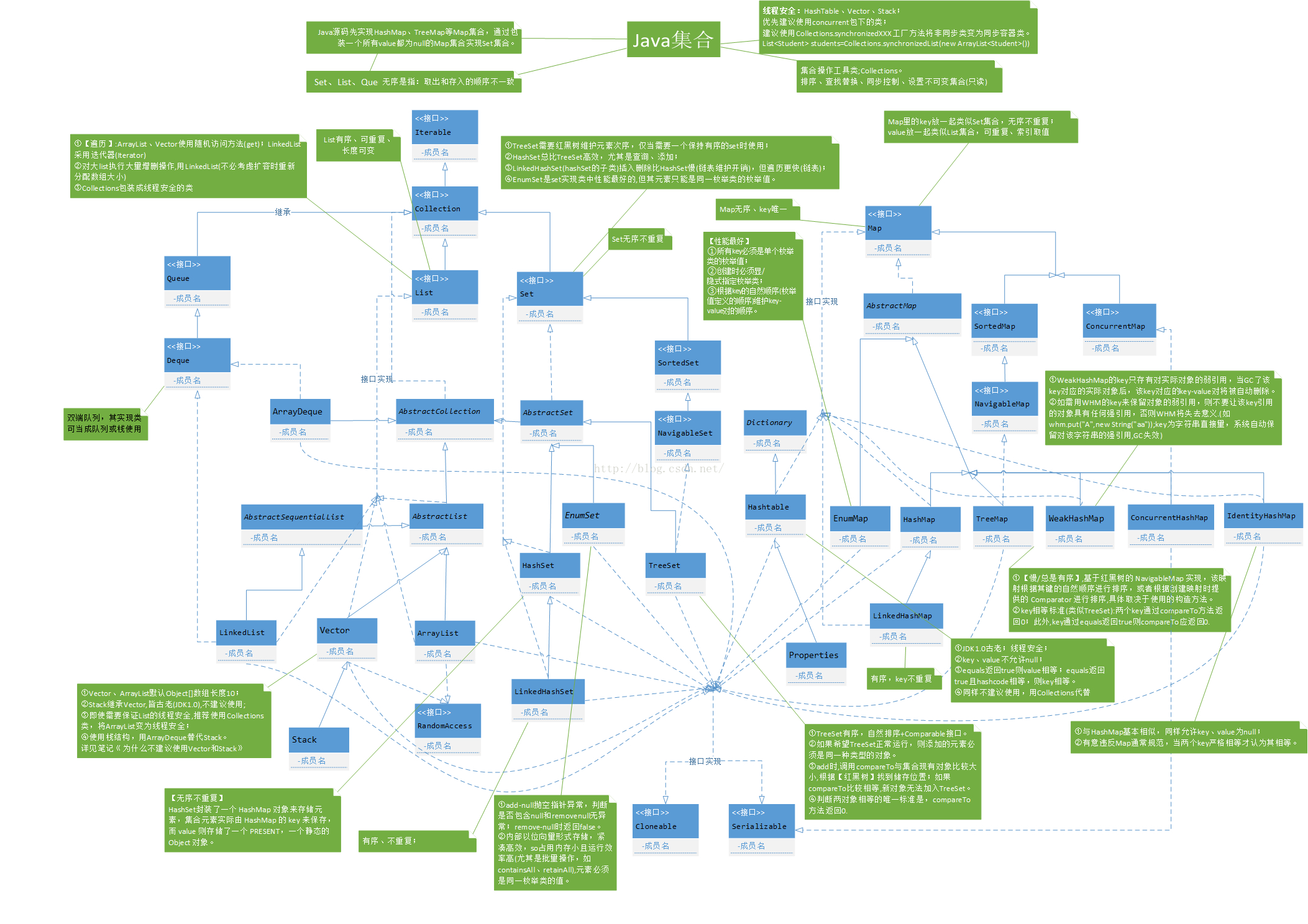
集合(各类集合区别)
单例
连接池(种类、配置)
线程池(j.u.c)
synchronized
static
常见异常
常用jvm垃圾回收
多线程使用
kafka和rabbitMQ区别
OOMError
SparkSql执行原理
当执行SparkSQL语句的顺序为:
1.对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等,从而判断SQL语句是否规范;
2.将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind),如果相关的Projection、Data Source等都是存在的话,就表示这个SQL语句是可以执行的;
3.一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize);
4.计划执行(Execute),按Operation–>Data Source–>Result的次序来进行的,在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。
sqlContext的运行过程
sqlContext总的一个过程如下图所示:
1.SQL语句经过SqlParse解析成UnresolvedLogicalPlan;
2.使用analyzer结合数据数据字典(catalog)进行绑定,生成resolvedLogicalPlan;
3.使用optimizer对resolvedLogicalPlan进行优化,生成optimizedLogicalPlan;
4.使用SparkPlan将LogicalPlan转换成PhysicalPlan;
5.使用prepareForExecution()将PhysicalPlan转换成可执行物理计划;
6.使用execute()执行可执行物理计划;
7.生成SchemaRDD。
mr
问题
1 | HR: |